Цель:
Отобразить стандартную схему размещения приложения, с пояснениями почему именно так.
Схема:
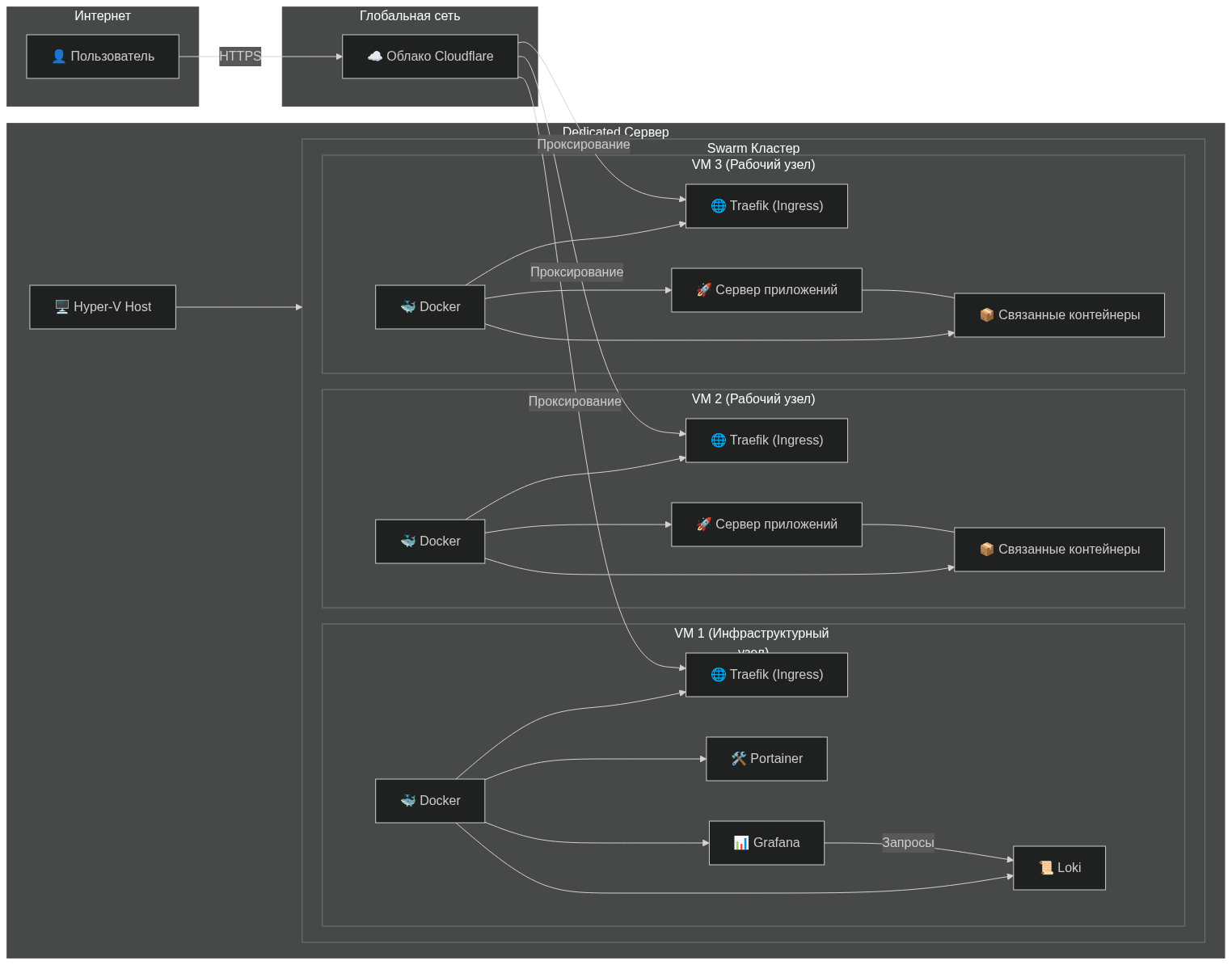
Элементы
CloudFlare
Мы используем CloudFlare чтобы скрыть IP адрес сервера. Не зная IP адрес, злоумышленники не cмогут определить физическое местонахождение сервера. Что защищает нас от двух проблем:
- переполнение входящего канала На уровне сети, даже если я настраиваю блокировку какие-то отправителей по IP подсетям, для откидывания пакета на уровне firewall он должен быть по прежнему доставлен на машину. Это создает возможность просто забить входной канал к машине, до применения любых фильтрова на самом сервере.
- abuse атаки на хостера. Зная IP я могу писать злые письма, о том что там детское порно лежит. Хостеру проще отключить сервер, чем разбираться с правомочностью жалобы
Dedicated Server
Мы обычно используем Dedicated сервера, вроде OVH, потому что на физическом оборудовании есть несколько плюсов:
- более современные процессоры чем в публичных облаках (2016й год vs 2024й)
- выделенный L1\L2 кеш. Многие оптимизации современных процессоров отключены в облачных решениях из-за соображений безопасности
- просто значительно более мощное оборудование Однако есть и минусы:
- отсутствие физического резервирования. В случае возникновения проблем с оборудованием - его замена не происходит моментально, что приводит к даунтаймам.
- физическое резервирование удваивает стоимость
- самому необходим реализовывать бекапы и прорабатывать сценарии восстановления из бекапов
HyperV host
На физический сервер мы раскатываем Windows хост систему. Это дает несколько преимуществ:
- возможность использовать проприетарные драйвера производителя оборудования (это может давать до 20% прироста к производительности)
- запуск всей полезной нагрузки в vhdx контейнерах, что позволяет их переносить между хостами
- поддержка HA реплицирования хостов, что позволяет сделать физическое резервирование или бекапирование виртуальных машин
- возможность жестко разделить физические ресурсы между виртуальными машинами (наш app сервер никогда не заест все ресурсы, потому что есть физическая привязка ядер процессора к виртуальной машине). Единственный не разделяемый ресурс у нас это входящий канал интернета (который мы защищаем используя CF)
Swarm кластер
Мы используем Docker Swarm, потому что он просто простой как палка и не ломается. Даже при обновлении не ломается. Даже если его случайно уронить. В целом поддержка проще чем у k8s. Для работы необходимо минимум 3 узла. Поэтому мы создаем 3 виртуальные машины и объединяем в один кластер. Один из узлов назначается мастером (обычно это инфраструктурный узел)
Инфраструктурный узел
Отдельная VM, на которой располагаются все вспомогательные сервисы для работы сервера.
- Grafana: как интерфейс для мониторинга
- Loki: как хранилище для логов
- AlertManager: для нотификаций о проблемах
- Portainer: для доступа к контейнерам напрямую
- другие сервисы, если они нужны
Рабочий узел
VM на котрой, собственно говоря крутиться полезная нагрузка.
- traefik: ingress контроллер, на уровне которого происходит управление сертификатами, блокировки и т.п.
- сервер приложений: само приложение, это может быть несколько контейнеров в ротации к примеру (на пример php - мы поднимаем 3 php контейнера и все запросы раскидываем между ними)
- связанные контейнеры: к примеру walg для бекапирования баз данных, odyssey как connection-pooler для базы данных и т.п.