# StatBet: A Comprehensive Sports Data Portal
Goal
Create Portal with actual info regarding sports
- Soccer
- NBA
- Tennis
Future expansion will include other sports like MMA and more
Design
Technology Stack
- SvelteKit — Frontend framework
- Cloudflare Pages — Hosting and CDN
- Cloudflare KV — Cache layer for BFF
- Strapi — Admin panel and API for content
- Meilisearch - search engine
- Temporal — Workflow management
- Fastify — performant http server for NodeJS
- Redis — Cache layer for Fastify\Strapi
- ChatGPT/Claude/Gemini — language models used for data processing
- PostgreSQL - SQL Database
- OVH.ie — Server hosting for Strapi/Temporal
- BigQuery — Long-term storage
- MetaBase — Dashboards and data linking
Project Structure
Project split to 3 parts.
- Front: this is a part for end-users, it uses some API and have aggressive caching, but mostly it's all about our users and UI.
- Admin panel: here we can work with content, tags etc.
- Data Gateway Service: this is a separate service that allows us to fetch data and make some preparation, validation steps, then put that data to DB.
Schema
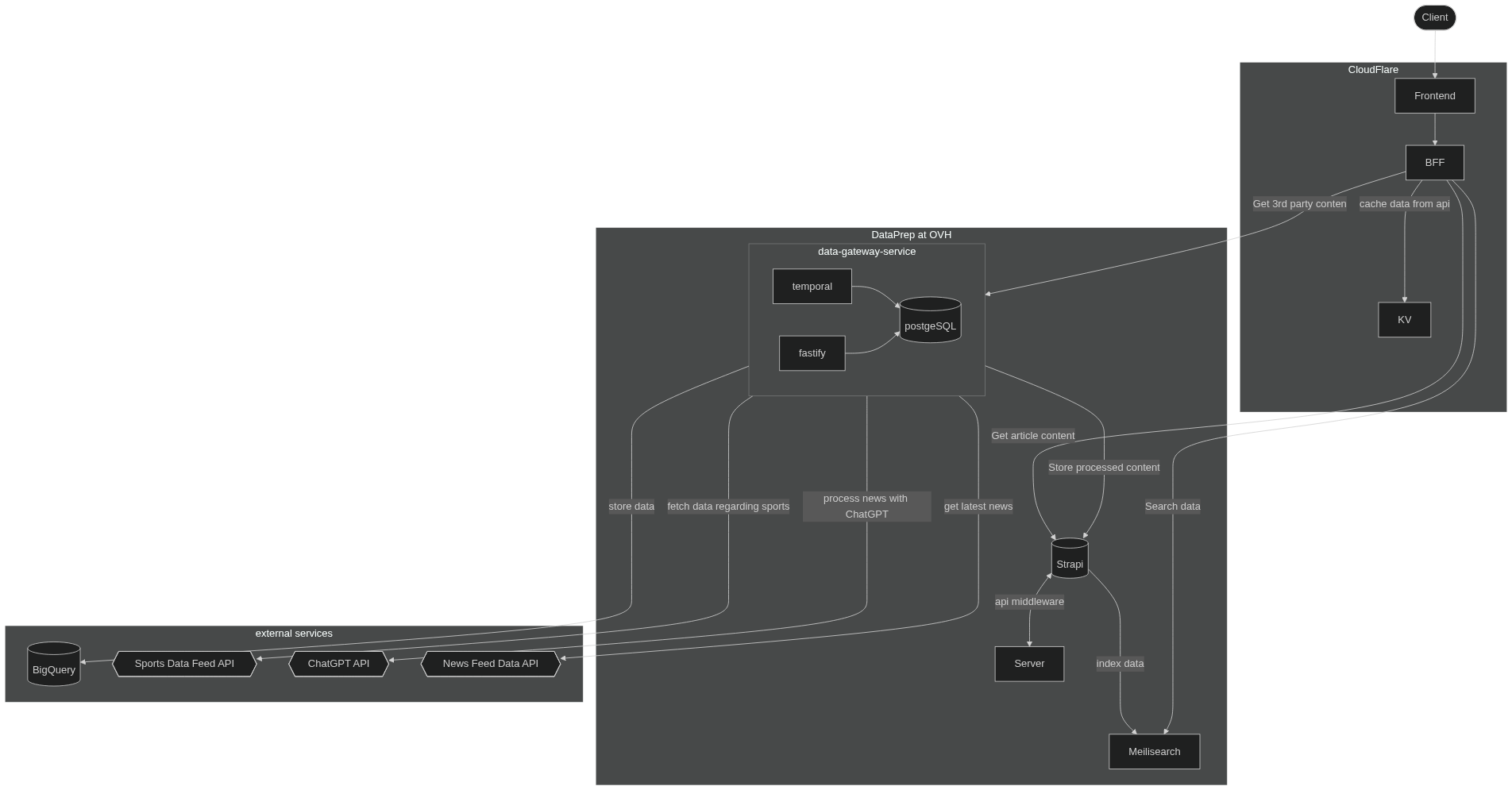
Front
This part uses fully custom design to provide the best user experience. We tried to use mobile-first approach in development, because of design issues we now two different layouts for some pages. Anyway in most cases we have component based design.
To separate external API from app data layer, we use BFF layer (Backend For Frontend). Here shines SvelteKit and CloudFlare pages. The main benefit of such stack is a built-in integration of BFF layer into app, which allows using strongly typed autogenerated interface between BFF and frontend. Because of that, it's easy to wrap any external API in BFF and decouple its shape from UI.
Also, we use KV to cache API responses on the edge to reduce amount of actual requests to backend.
For auth handling, we use Lucia, which stores auth data inside KV directly inside CloudFlare.
For integration with Strapi we have to build additional TypeScript models, which could not be avoided.
Admin panel
We didn't want to build custom admin panel for content management. But we have to provide some interface to manage users, their verifications, promts, other content etc., and we stick to Strapi within those tasks. Strapi is not designed for handling lots of requests, because of that we have caching layer at BFF layer (which is super performant). Strapi supports i18n for content types. We have to host Strapi as normal app in docker container, without CF Pages or other edge solutions.
The main goal of using a system like Strapi is to avoid building an admin panel ourselves. In it, we can create data scheme with point and click, and then use it as data source.
Danger: i18n realization in Strapi v4 is done by plugin, which leads to problems with querying data and performance issues. Strapi already released v5, where those issues solved, but we postponed update for now.
For asset storage we integrated CloudFlare R2. It's a flexible and pretty cheap solution to store lots of images. The egress traffic for R2 is free, that's why we use it instead of GoogleCloud or other S3 like storage.
Also, we use strapi to pre-process images, like generate AVIF versions and provide different sized versions. AVIF outperforms other formats for big images.
For 3rd party data we try to avoid using strapi as data layer, and make request to Data Gateway Service
Data Gateway Service
This is an umbrella for group of workflows, managed by Temporal. We have integrated with a few api providers, like DSG and SportMonks. But, unfortunately, they are not very reliable, that's why we shifted all data processing to Temporal workflows.
Actually fetching, merging, cleaning, extending, saving of any kind of data — is a workflow. Because of temporal we have a good observability of processes that we run, and It's easy to recover/retry/debug if something goes wrong.
Main workflows that we have:
- generate articles
- collect data from newsfeeds
- collect data from DSG
- collect data from SportMonks
- merge data across different sources
- store data in PG or Strapi
- extend data within external sources (like wikipedia)
- translate data
- etc…
Most of the workflows could be controlled by settings in strapi, like storing prompts, choosing which GPT model to use (OpenAI, Gemini, Clause) etc.
In most cases we automatically match data from different source, but in case of failure, we have a linking dashboard in Metabase, where admin can search for unmatched items and link them manually.
The resulting data stored in PostgreSQL, we have our own data matching index based on stb-internal-id, that we use to consolidate data from different sources, allowing us to easily remap entities between different providers.
List of API integrations:
- DSG
- SportMonks
- news api
- RSS api
- YouTube API
- Bing Image API
- Wikipedia
- Google Translate "free" api
- OpenAI ChatGTP
- Google Gemini
- Anthropic Claude
- Teleram
- Google Forms
Infrastructure components
We have a CI, that supports preview branches for each development branch (based on CloudFlare Pages). Most of the frontend parts lives on the CloudFlare Edge.
For Data Gateway Service we use Bare-metal server with Docker Swarm on it. As ingress controller we use Traefik. All services, like Strapi, Fastify, Temporal, PostgreSQL, Redis etc. stores their logs in Loki. We use Grafana to observe logs and metrics stored in it. Also we make use of AlertManager to send alerts to Mattermost/Telegram.
MetaBase works as a separate service connected to other services databases (direct access to PG and BigQuery).
We make incremental backups of databases using wal-g. All backups stored encrypted at CloudFlare R2.
Path to current solution
In the beginning, we adopted a much simpler approach to product implementation because we underestimated several challenges.
Initially, the project was built using Strapi and n8n. N8N is a custom visual workflow editor that allows users to visually modify data processing within workflows.
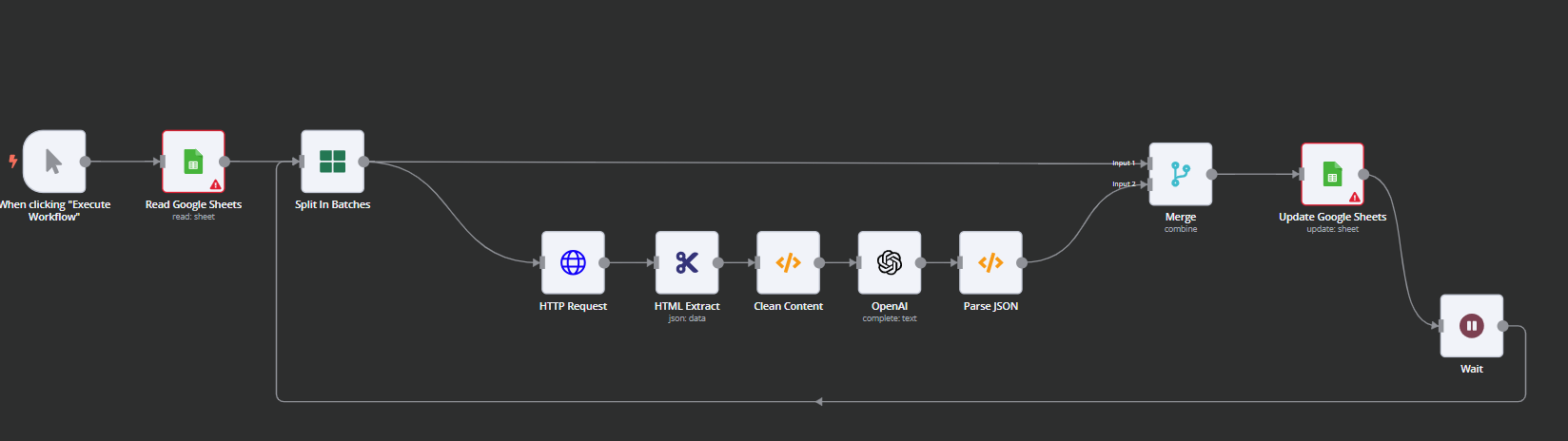 At first, we used n8n to build article generation and other content flows. However, we eventually had to discontinue using n8n due to the growing complexity of the flows. As new requirements for generation speed emerged, we needed to add parallelism to the n8n workflows, making them difficult for non-developers to use and challenging to support overall.
At first, we used n8n to build article generation and other content flows. However, we eventually had to discontinue using n8n due to the growing complexity of the flows. As new requirements for generation speed emerged, we needed to add parallelism to the n8n workflows, making them difficult for non-developers to use and challenging to support overall.
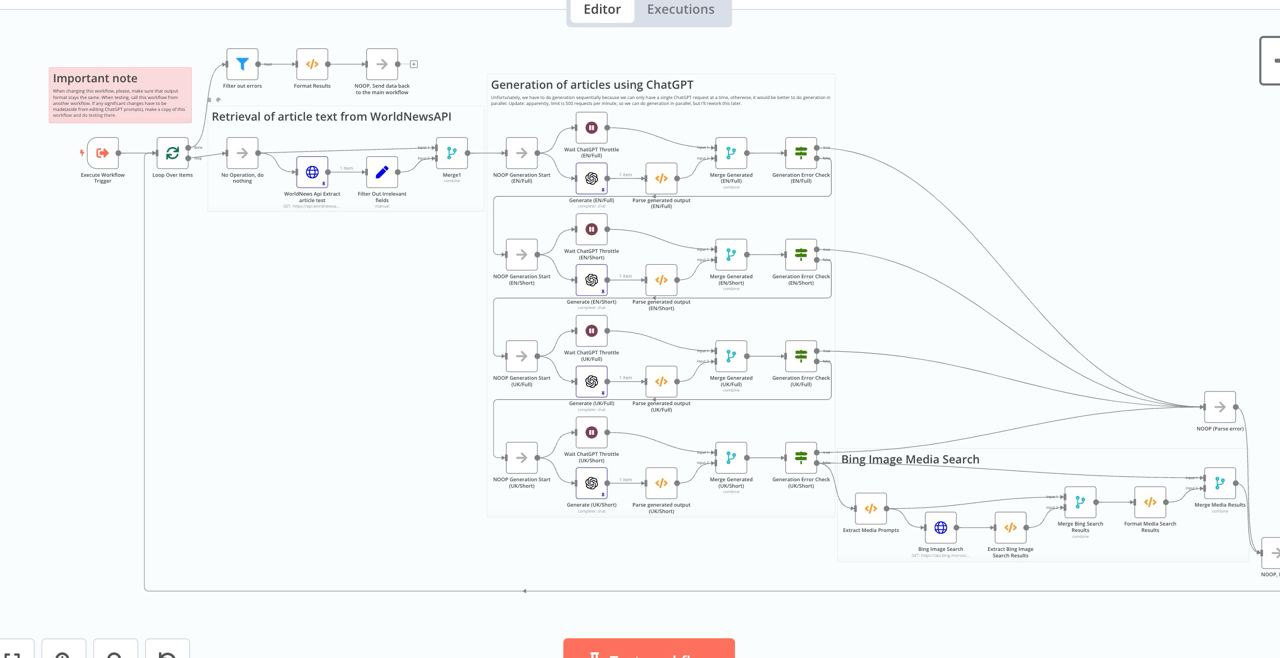 The positive aspect was that using n8n allowed us to quickly prototype different workflows and refine how they should function.
Subsequently, we moved all workflows to Strapi. This transition helped manage the complex workflows effectively, but over time, new issues arose. As we continued developing, we realized our integrations were not particularly reliable. Additionally, we encountered slow data updates in Strapi. We kept adding new data sources, and eventually, the volume of modifications required in Strapi exceeded its capacity.
At this point, we shifted to using Temporal, which offers common patterns for steps, retries, and error handling. All workflows were moved to Temporal, including external integrations. To avoid issues with update speed, we created an additional PostgreSQL database to store all the data. After that we started serving part of the data directly from DGW.
The positive aspect was that using n8n allowed us to quickly prototype different workflows and refine how they should function.
Subsequently, we moved all workflows to Strapi. This transition helped manage the complex workflows effectively, but over time, new issues arose. As we continued developing, we realized our integrations were not particularly reliable. Additionally, we encountered slow data updates in Strapi. We kept adding new data sources, and eventually, the volume of modifications required in Strapi exceeded its capacity.
At this point, we shifted to using Temporal, which offers common patterns for steps, retries, and error handling. All workflows were moved to Temporal, including external integrations. To avoid issues with update speed, we created an additional PostgreSQL database to store all the data. After that we started serving part of the data directly from DGW.
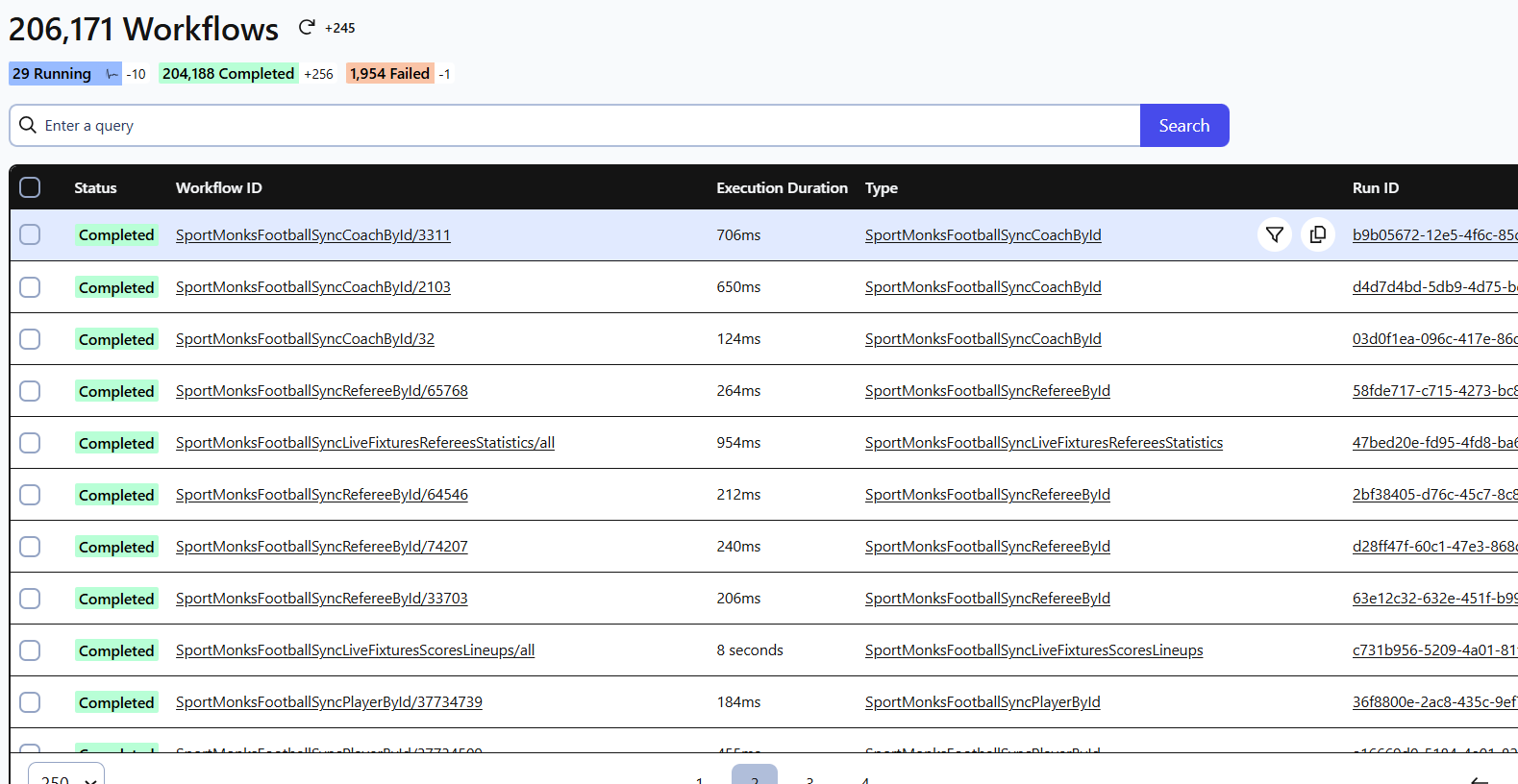
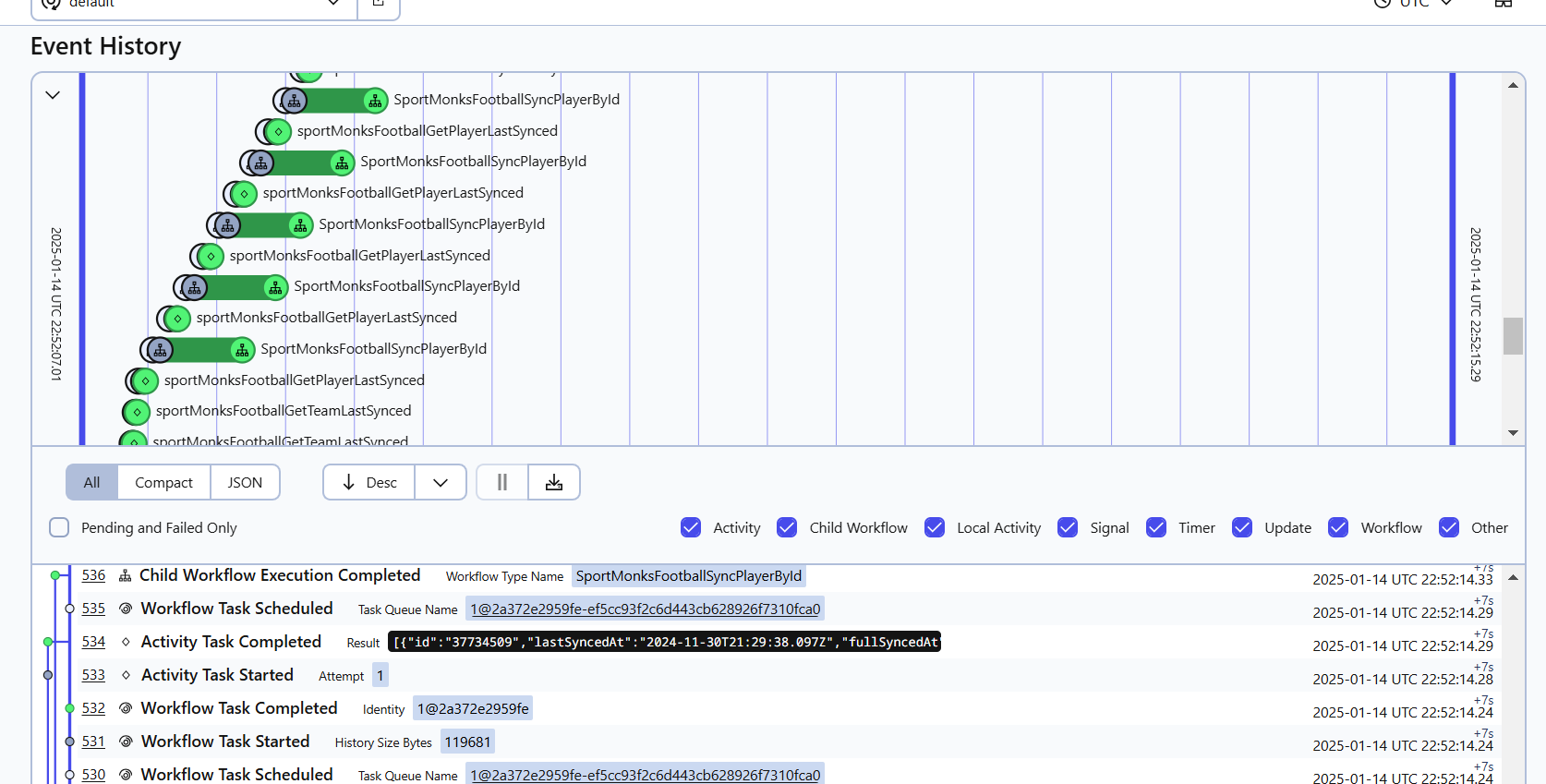 In current architecture is much easier to handle data integrity tasks, by generation of a new system workflows.
In current architecture is much easier to handle data integrity tasks, by generation of a new system workflows.