App Flow Diagram
Actors:
- User
- Frontend
- API server
- Game Machine
- TURN server
When users want to play, then he loads a frontend, which connects to api server, to obtain list of available game devices. When user makes a choice to interact with exact game device - api server creates connection directly from player to game device. After that over that connection we establish video stream from user to game device. There are 2 cases. If user has “white” IP address we setup direct connection. If user is behind NAT, and have no exposed IP, then we setup intermediate connection to TURN server, which works like a relay to send video/audio data.
Fault Tolerance. Reservation of system components.
For API Server we use reservation with containers, if API container goes down we spinup new one in another cluster. It allows us to work with minimal downtime. Because all components are in container we are really fast in starting new instances.
For FrontEnd we use Firebase Hosting, which has SLA. It means that in most cases we don't have to worry about frontend part of an app.
For DataBase we use BigQuery, which has SLA also. But we have additional protection, that disables all the system if BQ is not working for some reason.
For TURN servers we have a server reservation in different regions, we put one server on each continent. If one is going down — all connections will just switch to another one. For RTP Connections it's super crucial to have lower as possible latency, that's why we usually support a list of TURN servers in a few geo regions.
How we store information regarding logs?
We use Loki as a storage for logs, and Grafana to query those logs. For events that represent critical errors we use Prometheus as monitoring and send them into special chat with alerts in Telegram. This gives option to quickly react on errors and outages.
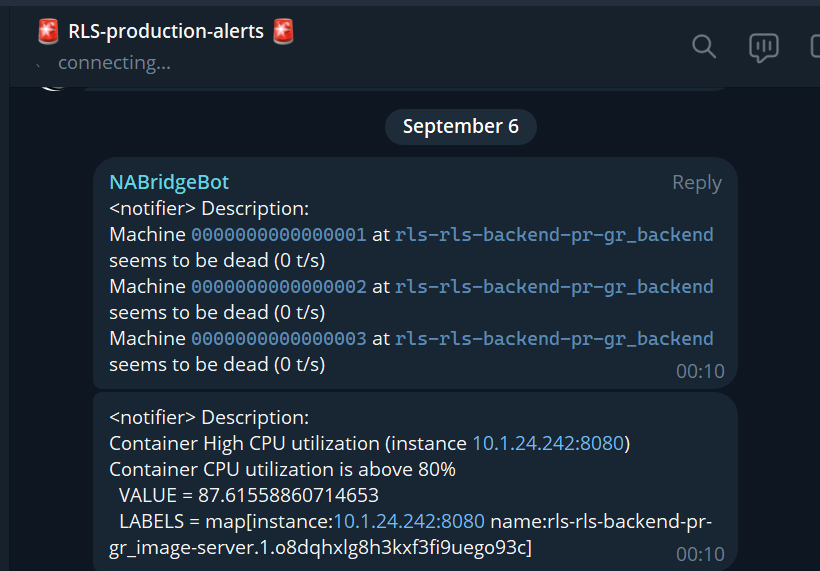 On a screen above you can see the case, when internet was gone, and devices stopped streaming of the video. We have 0 bitrate for those devices (no video come from devices).
On a screen above you can see the case, when internet was gone, and devices stopped streaming of the video. We have 0 bitrate for those devices (no video come from devices).
Firewall logs
We don't have special Firewall logs, but we use CloudFlare WAF, which has reporting of incidents, and stores most information about incoming requests.
Where and how backups created?
We make copy of all data to Google Cloud. Like long term storage we use Google Cloud Buckets. Actually if streaming to Google Big Query (our system to store history of all events) fails — we block work of the system, event if some other parts are operational. BigQuery allows us to store transactions without limitations in time.
Locations of server infrastructure.
Where our servers located: Our server location:
- for API we use dedicated servers in OVH Frankfurt datacenter
- for FrontEnd part we use Firebase Google, which is distributed CDN
- for TURN servers we use different zones across DigitalOcean network
Backoffice description:
We use MetaBase to provide reporting for both — internal team and external agents.
You may take a look at reports by visiting:
URL: https://realliveslot.com/dashboard
login: demo
pass: demo
Link with password.
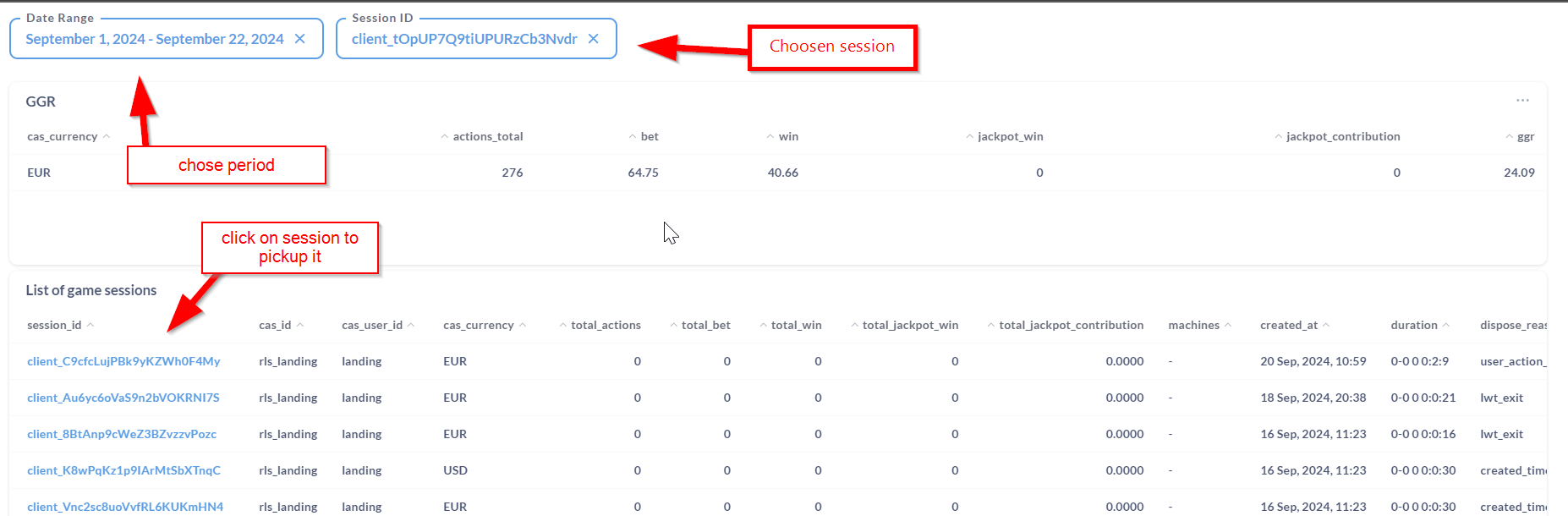
Report consists of two parts: session list, and session info.
Session list:
 Session Info:
Session Info:
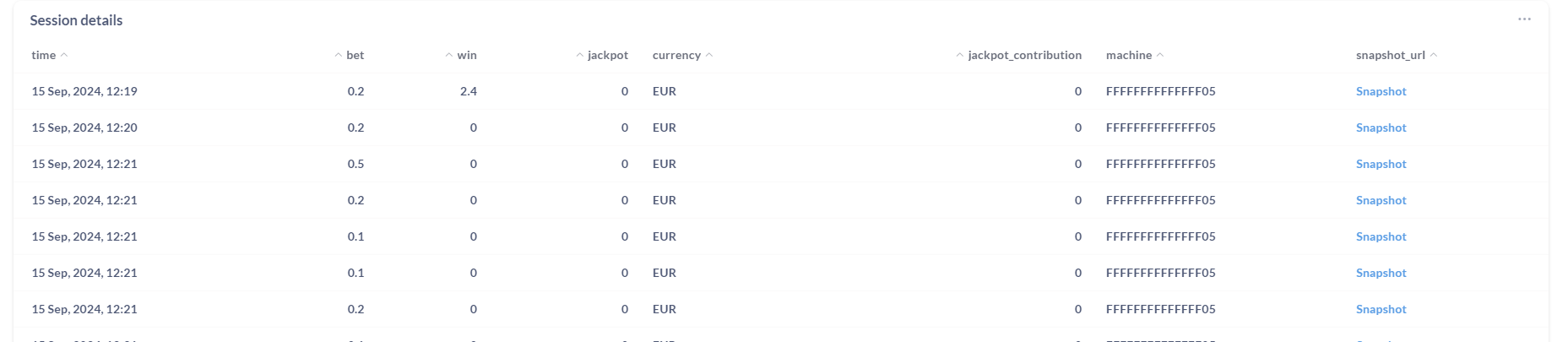 Clicking on snapshot will open stored video of winning screen.
Clicking on snapshot will open stored video of winning screen.
todo:
- обговорить аудит penetration testing
- хеш суммы контейнеров (критические компоненты) (git tags) 29.01.2024 заявка, версия 1.8.24, имя RealLiveSlot, CMS (casino management streaming)
How we handle bugs and other errors
Flow of handling errors/issues:
- at first we put down report into Jira
- then responsible employee tries to reproduce an issue on prod/stage environment, and provides additional information regarding issue. (like logs, videos anything that can help to understand what was wrong)
- if some changes should be applied, developer makes them and rolls out to stage environment.
- If issue is solved on a stage responsible employee makes new build and updates production environment.
How we make an audio/video channel reservation?
We have more than one internet provider in a physical place where we put devices. If our main provider goes out for some reason, our router (that acts like a gateway for internal network) makes a switch to reserve internet provider. In most cases it's done automatically, but if not — operator can manually switch between providers.
Network schema: